Some of the hardest work in retail analytics happens long before dashboards, forecasts, or machine learning models.
It begins with a much less glamorous challenge: making sure “the same product” is actually the same product across systems.
In a typical supermarket, there were 31,795 items on the shelf on average in 20241. Across suppliers, distributors, and point-of-sale systems, the data behind those items is often fragmented, inconsistent, and noisy. GS1 reports that retailers may need 10–15 interactions with suppliers to launch each SKU, and that they face ~15,000 issues with inaccurate product data per year on average.2
Now bring that same complexity into point-of-sale feeds.
Vendor item descriptions vary by location, operator habits, abbreviations, upstream POS software, and whatever someone happened to type at the register. The result is a persistent matching problem: expensive to outsource, expensive to manage manually, and still expensive when it is “solved” with brittle rules that break as soon as the data gets messy.
I built an Snowflake Cortex AI-powered solution to this problem in three calendar days.
Not three days of nonstop coding. More like a handful of real hands-on hours. The rest was Cortex Code CLI doing the heavy lifting while I guided the architecture, reviewed the output, tested the logic, and kept refining the system until it behaved the way I wanted.
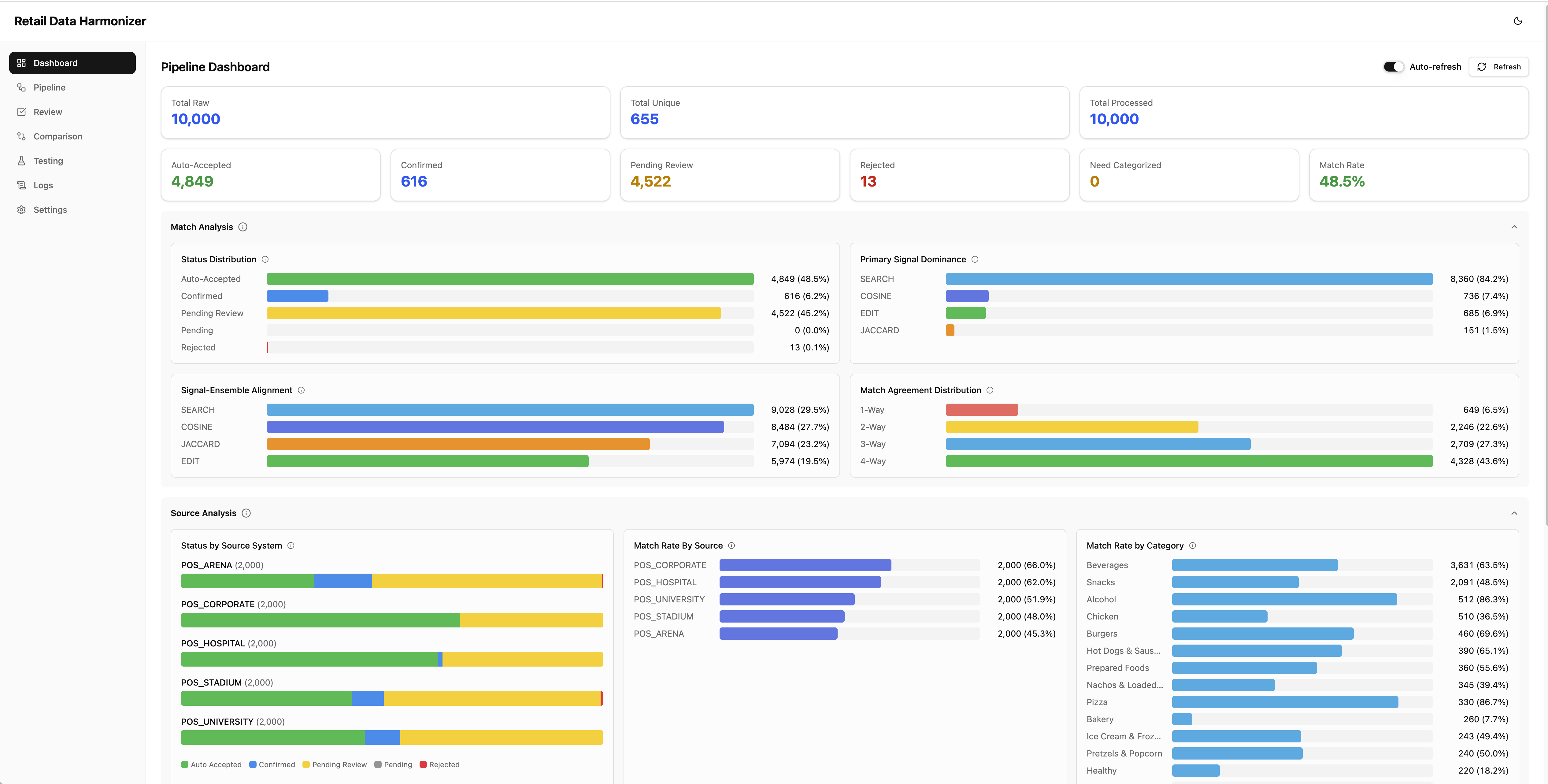
What came out of that sprint was more than a demo. It was a working matching pipeline with de-duplication, multi-method scoring, human review, cached learning, and test instrumentation. On the current working sample, the system reduces 10,000 raw records to 655 unique descriptions, processes 9,932 items through the matchers, and isolates 68 blocked records upstream because of missing category classification.
Here’s how I built it, what mattered most, and why I think it offers a glimpse of how experienced builders will work with AI going forward.
The Problem: Same Product, Dozens of Descriptions
Retail data is messy in exactly the way that breaks elegant solutions.
Point-of-sale systems from Micros, Clover, NCR, and dozens of other vendors all use their own conventions. This extends behind descriptions to schema-level differences – field names, data types, category taxonomies and export granualarity all vary by vendor. Operators abbreviate differently. Source systems disagree. Descriptions get truncated. Word order changes. Sizes disappear. Brands get shortened into cryptic fragments that only make sense if you’ve lived with the data long enough.
A single 20oz Coca-Cola bottle might show up as:
COKE 20OZ BTLCoca-Cola Classic 20 oz20 OZ COCA COLAcoke bottle (20oz)CK CLA 20OZ BTL
That last one is the kind of example that breaks naive matching systems.
If you know the domain, a person can infer that CK means Coca-Cola and CLA means Classic. But a strict rules engine won’t know that unless someone explicitly teaches it. And even if you do teach it, you’ve now signed up to maintain a giant pile of exceptions forever.
POS Item Matching Is Really Identity Resolution
At its core, POS item matching is a master data problem.
You start with messy, vendor-specific descriptions captured at the register. You want to map each one to a single canonical product in a master item list with stable attributes like:
- brand
- pack size
- unit of measure
- category
- subcategory
- internal item identifier
Without that harmonization, even basic business questions get harder than they should be:
- What did we actually sell, by brand, category, and pack size?
- Are we pricing consistently across locations?
- Are we buying the same product from multiple vendors under different descriptions?
- How much noise is making its way into downstream analytics?
This isn’t glamorous work, but it is foundational. If the product identity layer is wrong, everything built on top of it gets shakier.
Why the Usual Approaches Break Down
Traditional approaches all fail in predictable ways:
-
Manual mapping is expensive, inconsistent, and non-compounding. Every analyst builds slightly different mental heuristics. One person maps
CK CLA 20OZto Coca-Cola Classic. Another flags it as unknown. When someone leaves, their institutional knowledge walks out the door and the next person starts over. The work never compounds because nothing about it is systematic. -
Rule libraries are fragile and turn into operational debt. You write a rule that says “CK = Coca-Cola.” It works until a new supplier sends
CKmeaning something else entirely. Every new edge case means another rule, another exception, another branch in a decision tree that nobody fully understands anymore. Over time, the rule library becomes its own maintenance burden — a growing pile of brittle logic that someone has to own, debug, and extend indefinitely. -
Lookup tables and vendor-provided crosswalks assume clean, consistent input. They work when both sides use the same identifiers. They break the moment a description is truncated, abbreviated, or entered freehand at the register. A lookup table has no way to infer that
CK CLA 20OZ BTLshould resolve to the same product asCoca-Cola Classic 20 oz. -
Regex and pattern matching can handle known abbreviation patterns but cannot generalize. You can write a regex that catches
20OZand20 ozand20-oz, but you will never enumerate every variation across thousands of products and dozens of source systems. The maintenance cost scales linearly with product catalog size and source system diversity. -
Outsourcing shifts the labor cost but does not eliminate it. Third-party data services charge per-record fees and still rely on human reviewers working from the same ambiguous descriptions. Turnaround times are slow, feedback loops are long, and the institutional learning stays with the vendor, not with you.
-
Single-model approaches help, but every method has blind spots. A pure embedding model handles paraphrases well but misses domain-specific abbreviations. A lexical matcher catches token overlap but fails when word order or phrasing changes. No single method reliably covers the full range of ways that messy POS descriptions can differ from clean canonical records.
That is why this was such a strong candidate for an ensemble.
I didn’t need one perfect algorithm. I needed a system where different methods could cover each other’s weaknesses, and where human review could improve the economics over time instead of cleaning up the same mess again and again.
The Build: Three Days, Mostly Guided by AI
Day 0: Get Something Working Fast
I started with Cortex Code CLI and my personal ai_coding_rules framework.
The framework is basically a structured ruleset I’ve built over time for working with AI coding assistants. It loads project conventions, Snowflake patterns, SQL expectations, and implementation guardrails before the assistant starts generating code. In practice, that changes the quality of the output a lot. The AI is no longer starting from zero. It starts with context.
My first prompt was intentionally simple:
Create a data harmonization pipeline that maps raw retail descriptions to standard items using Snowflake Cortex AI.
Within a couple of hours, I had a functioning prototype:
- raw item tables
- standard item tables
- match result tables
- de-duplication logic
- a basic CLI
- a first-pass matcher built around
Cortex Search
That first version wasn’t production-ready, but it proved the core idea: this problem could be tackled inside Snowflake with AI functions, SQL procedures, and a lightweight app layer.
Days 1–2: Build the Ensemble, Not Just a Matcher
The single-method prototype was useful, but it wasn’t enough.
Different matching methods are good at different things:
| Method | What it helps with |
|---|---|
Cortex Search |
Abbreviations, lexical overlap, hybrid semantic retrieval |
| Cosine similarity | Semantic equivalence and paraphrase-like matches |
| Edit distance | Typos, small variations, character-level drift |
| Jaccard similarity | Token overlap independent of word order |
What mattered wasn’t picking a winner. It was combining the methods into a system that could make better decisions when they agreed and behave more cautiously when they didn’t.
So I had Cortex Code build all four methods, then combine them into an ensemble with agreement-aware scoring.
That was the point where the collaboration pattern became obvious:
Cortex Codegenerated the implementation quickly- I made the architectural decisions
Cortex Codetranslated those decisions into code- I tested the outputs and corrected the logic where needed
This matters because people sometimes talk about AI coding assistants as if they either “write the app” or “can’t be trusted.”
The reality is more nuanced.
They are extremely good at turning well-scoped intent into working implementation. They are not good enough to replace judgment.
That judgment still mattered:
- deciding which methods should dominate
- setting routing thresholds
- checking for subtle scoring bugs
- catching joins that technically ran but semantically misbehaved
- deciding what should be auto-accepted versus reviewed by a human
One of my favorite moments in the build came when I described a fast-path cache in plain English:
If a human confirms a match, store it so the next identical description skips AI entirely.
Cortex Code turned that into a real implementation with tables, procedures, and pipeline integration in minutes. That is the kind of leverage I keep seeing with these systems: if you can clearly define what should happen, they can often turn it into reality very quickly.
Day 3: Make It Operational
By the third day, the matching logic basically worked.
Now the job was to make the system behave like something you could actually run.
That meant adding:
- a testing framework
- status and observability views
- a review workflow
- background processing
- confirmation caching
- clearer routing between auto-accept and human review
In the current working batch, the dashboard shows 4,849 auto-accepted items, 616 human-confirmed matches, and 4,522 items waiting in review, with an overall 48.5% match rate at that stage of the workflow.
That distribution is actually a feature, not a bug.
I didn’t want a system that pretended to be more certain than it was. I wanted one that would confidently automate the obvious cases, surface the ambiguous ones, and learn from reviewer decisions over time.
The Architecture: Four Signals, One Decision
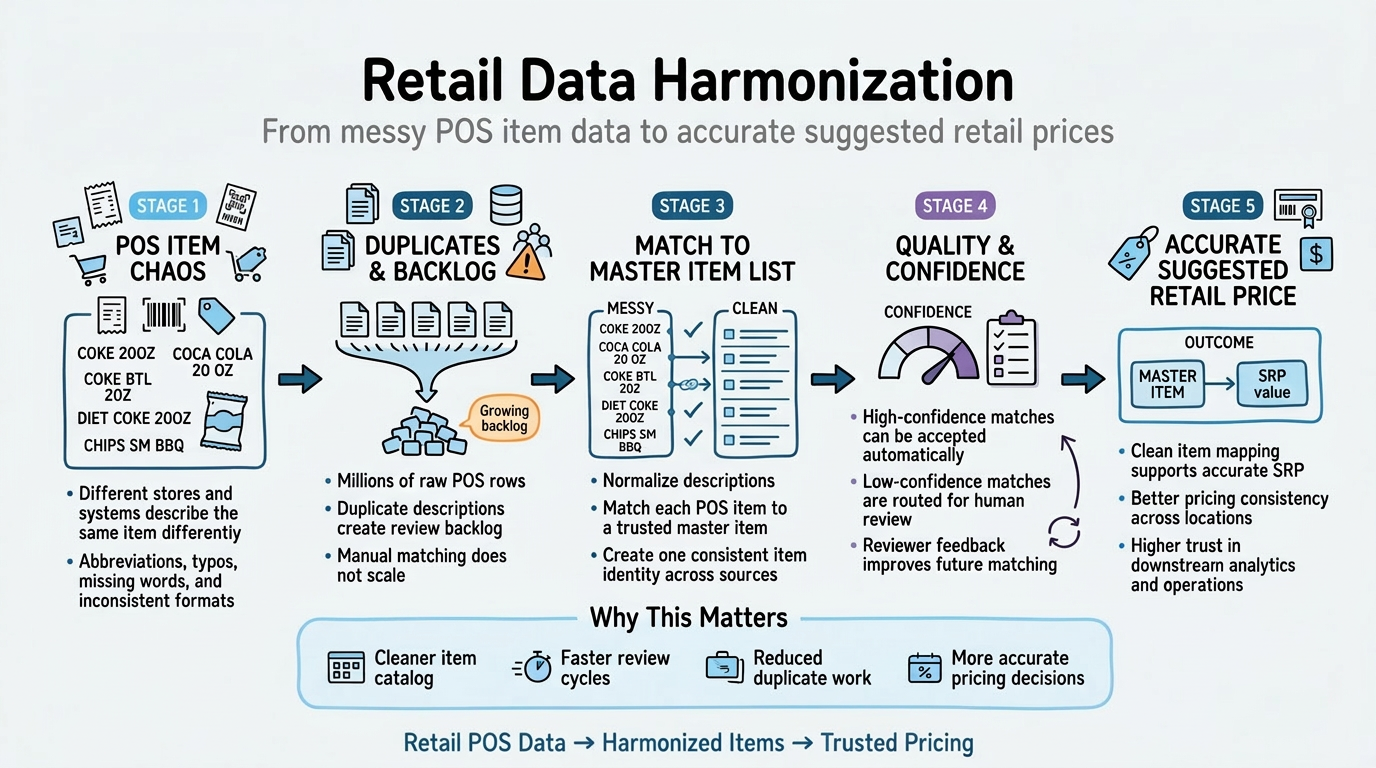
Architecture Diagram
Data flows from raw items through de-duplication, matching, and scoring
The final design is easiest to think about as a sequence:
- normalize and de-duplicate raw descriptions
- score candidate matches using multiple methods
- reward agreement across methods
- route the result based on confidence
- capture human feedback and reuse it
Step 1: Collapse the Problem Before You Throw AI at It
This was one of the highest-leverage design choices in the whole system.
The raw backlog was huge, but much of it was repetitive. Instead of matching every record independently, I normalized descriptions and collapsed them into unique forms before scoring.
That changes the economics immediately.
On the current sample run, the pipeline shows a 93.4% de-duplication ratio, reducing 10,000 raw items to 655 unique descriptions before the matching stage.
That is exactly the kind of optimization that matters in real AI systems. If you can avoid expensive repeated work, you should.
Step 2: Let Different Matchers Do Different Jobs
I didn’t expect any one method to dominate every case.
Cortex Search is especially valuable here because retail abbreviations often require both lexical and semantic signals. A pure embedding comparison can miss domain shorthand. A purely lexical matcher can miss semantic equivalence. Search gives you a useful middle ground.
Cosine similarity helps when the wording differs but the meaning stays close.
Edit distance helps with misspellings and small textual mutations.
Jaccard helps when token overlap is strong even if word order changes.
The real power comes from using them together.
Step 3: Use Agreement as a Confidence Signal
The comparison view made this pattern very clear.
When all four primary matchers agree, the average confidence is about 0.8927 across 4,328 cases. When none of them agree, average confidence drops to about 0.5018 across 649 cases.
That is a much more useful operational signal than any single raw score.
Agreement isn’t magical, but it is practical. If multiple fundamentally different methods converge on the same answer, you should trust that answer more than a single high score from one method acting alone.
That insight became a core part of the ensemble logic.
Step 4: Route With Humility
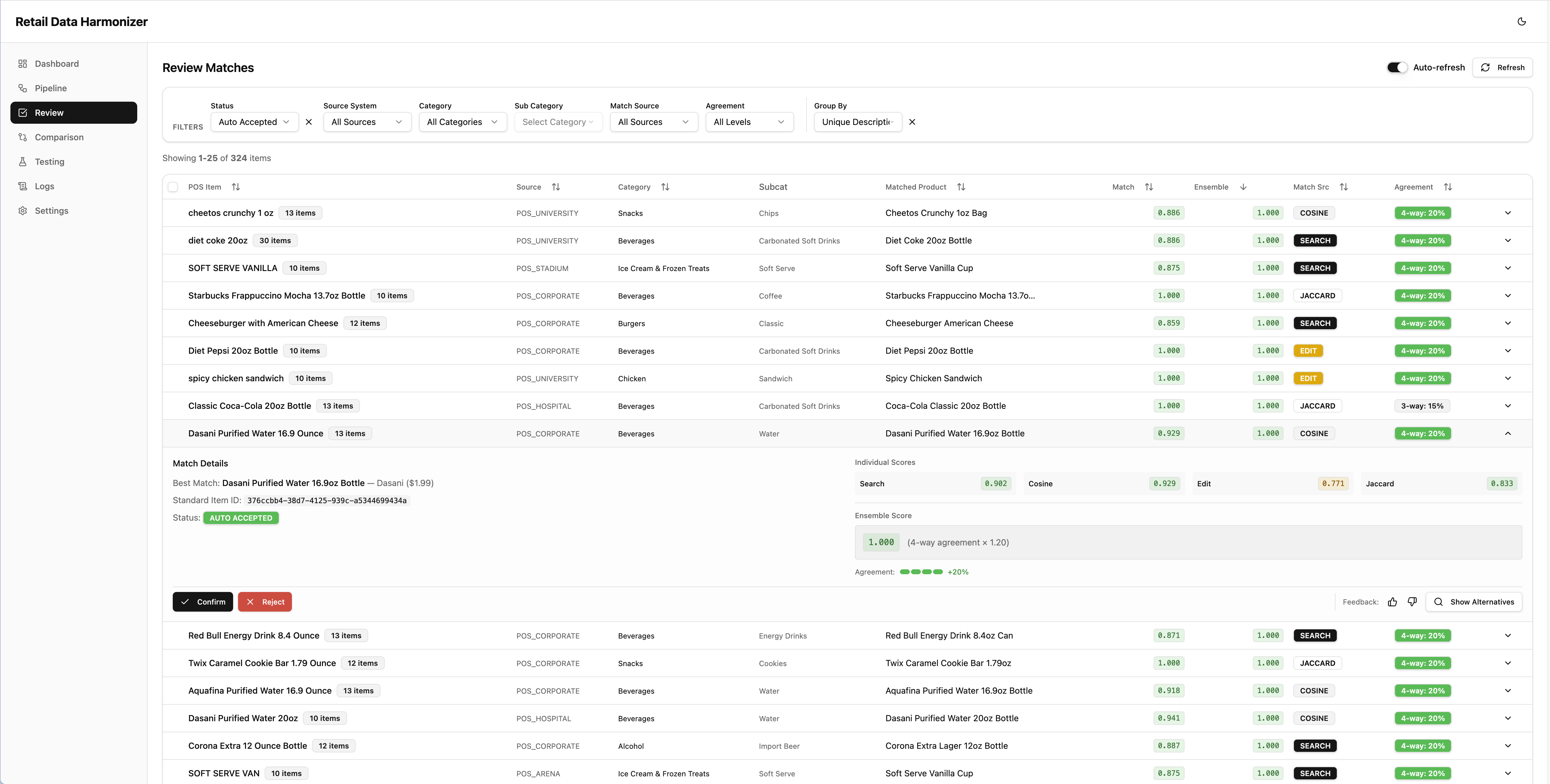
The review UI is where the system becomes usable.
For each proposed match, the reviewer can see:
- the suggested standard item
- the ensemble score
- the individual method scores
- the agreement pattern
- controls to confirm or reject the match
That means the AI is not operating like a black box. It acts more like a triage system with visible evidence.
That matters operationally because it makes human review faster, safer, and easier to teach.
Step 5: Turn Human Review Into a Compounding Asset
The cache is the long-term cost play.
Once a reviewer confirms that a given description maps to a canonical item, the system stores that result. The next identical description can skip the expensive reasoning path and resolve immediately.
That means human review is no longer pure labor. It becomes training-by-confirmation.
Every confirmed match increases the chance that future work becomes cheaper.
What the Working System Looks Like Today
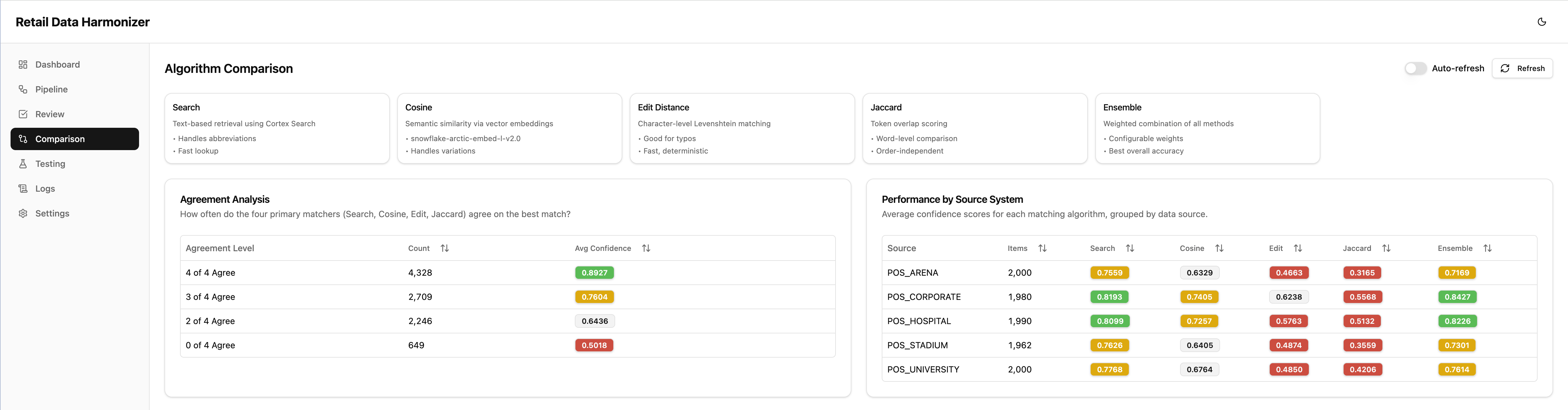
Accuracy Results
Per-method accuracy comparison on the test set
The current implementation is not just conceptually sound. It is visibly instrumented.
The pipeline view shows all major matching stages completing on the sample batch, including Cortex Search, cosine matching, edit distance, Jaccard matching, and the ensemble stage, with 9,932 of 9,932 eligible items processed through the matchers.
The dashboard also shows which signals dominate the current run. SEARCH is the primary signal for 84.2% of items, with cosine, edit distance, and Jaccard each contributing smaller portions of the decision mix.
That lines up with what I expected from the domain. Retail abbreviations and shorthand descriptions often benefit most from a strong retrieval signal.
Validation: The Hard Cases Matter Most
This is where the project got more interesting.
The testing view shows a validation run with 135 total tests across 5 methods, split into 37 easy, 43 medium, and 55 hard cases.
That distribution matters because easy examples can make any system look good. The real question is whether it still behaves when the descriptions are ugly, abbreviated, partial, or misleading.
On that broader test set:
- the ensemble reached 82.2% top-1 accuracy, 95.6% top-3, and 96.3% top-5
CORTEX_SEARCHreached 80.7% top-1- cosine similarity reached 77.3% top-1
- Jaccard and edit distance lagged meaningfully behind as standalone methods
The difficulty breakdown is even more useful:
- on easy cases, the ensemble reached 94.6%
- on medium cases, it reached 93.0%
- on hard cases, it reached 65.5%
That is exactly the kind of profile I would expect from a system like this.
Easy and medium cases are where automation pays off immediately. Hard cases are where the review workflow and feedback loop become essential.
In other words, the goal is not to eliminate humans. The goal is to reserve human attention for the cases where it creates the most value.
What I’d Do Next
The next phase is fairly straightforward:
- run the system against larger real-world production slices
- expand the ground-truth test set
- tighten thresholding by category and source system
- grow the confirmation cache
- track longitudinal improvements in automation rate and review burden
The source-level comparison view already hints that performance varies by input system, with average ensemble confidence ranging roughly from the low 0.71s to the mid 0.84s depending on source. That is exactly the kind of operational insight you want before deploying broadly.
That variance is not just a tuning detail. It is a diagnostic signal.
When a specific source system consistently produces lower ensemble confidence, it tells you something actionable about the upstream data. Maybe that POS vendor truncates descriptions more aggressively. Maybe a particular location or operator group uses nonstandard abbreviations. Maybe one integration feed strips out brand names or pack sizes before the data ever reaches your pipeline.
Once you can see those patterns per source system, you stop treating matching failures as a problem with the matching logic and start treating them as evidence of a data quality issue at the point of origin. That is a fundamentally different conversation — one that moves from “fix the matcher” to “fix the feed.”
In practice, this means you can prioritize root cause analysis where it matters most. If one source system accounts for a disproportionate share of low-confidence matches or review queue volume, that system becomes the highest-leverage target for upstream improvement. You might work with that vendor to standardize their export format, add missing fields, or enforce description length minimums. Each improvement at the source compounds downstream — fewer ambiguous records, higher auto-accept rates, and less human review burden.
Over time, the per-source confidence scores become a feedback mechanism for the entire data supply chain. They turn the matching system into a measurement tool, not just a resolution tool. You can track whether upstream changes actually improved data quality by watching how confidence distributions shift after a vendor makes a fix.
That is the kind of operational leverage that a well-instrumented ensemble gives you. It does not just match records. It tells you where the records are hardest to match, and why.
Different systems generate different flavors of mess. The right production architecture should acknowledge that instead of pretending all noisy text is the same. You can use the signals from each source system as a means of improving those feeds. Instead of wondering why POS 1 and POS 500 are different, you have signals that can be used to effect positive change.
Closing Thought
Three calendar days. A handful of real hands-on hours. That is what feels new — not because AI suddenly made software engineering trivial, but because it changed the economics of execution. I spent less time typing and more time deciding. Less time scaffolding and more time designing. Less time grinding through implementation and more time shaping behavior.
That shift is what makes Snowflake Cortex AI and Cortex Code a genuine force multiplier.
Cortex AI meant I never had to leave the platform to get intelligent behavior. Embeddings, classification, semantic search, and completions all ran where the data already lived. There was no model hosting to manage, no inference endpoints to provision, no data movement to orchestrate. The AI capabilities were just there — native functions I could call from SQL and stored procedures like any other part of the platform.
Cortex Code meant the gap between intent and implementation collapsed. When I described what the ensemble should do, it generated the procedures. When I defined the caching logic in plain English, it built the tables and the pipeline integration. When I needed four different matching methods wired into a scoring framework, it produced working implementations I could test and refine in minutes instead of days. In practice, it was especially good at generating boilerplate quickly, implementing repetitive SQL patterns, wiring together procedures and views, scaffolding interfaces, and iterating rapidly on narrowly scoped change requests.
What still depended on me was recognizing the actual business shape of the problem, deciding which signals mattered, defining routing behavior, spotting subtle logic defects, and knowing what “good” should look like before the code existed.
Together, they changed what one person could build in a weekend. And that matters because the bottleneck in most organizations is not a shortage of ideas or talent. It is the cost of turning a well-understood problem into a working system. When that cost drops by an order of magnitude, problems that sat in backlogs for years because the ROI never penciled out suddenly become viable projects.
This is not about replacing experienced builders. It is about removing the friction that keeps them from acting on what they already know. The expertise still matters — the domain knowledge, the judgment about what to build, the instinct for when to trust automation and when to require a human in the loop. What changed is the cost of expressing that expertise as a working system.
That is the real story here. AI did not replace expertise. It made expertise more scalable.
You can access the code repo here: retail_data_harmonizer
The project uses Snowflake Cortex AI (AI_CLASSIFY, EMBED_TEXT_1024, Cortex Search), a FastAPI backend, React frontend, and a Python CLI built with Typer. The ensemble scoring, accuracy testing framework, and observability views are all implemented as Snowflake stored procedures.
Footnotes
-
FMI — Food Industry Facts, “How many items do supermarkets carry?” (2024). https://www.fmi.org/our-research/food-industry-facts ↩︎
-
GS1 — “Everyone needs better product data” (accessed 2026-03-23). https://www.gs1.org/standards/gs1-global-data-model/everyone-needs-better-product-data ↩︎